

Author

Swiss AI Summit
Press , Swiss AI Summit
Published on:
June 30, 2026
From Code Completion to Autonomous Coding Agents
Key Takeaways from our Vibe Coding Session hosted by OST
Guided by the experts from OST, we explored how AI-powered coding has evolved from simple code completion to autonomous coding agents, and what this shift means for software engineering practice. Through a combination of theory, live demonstrations, and hands-on exercises, participants gained practical experience with the latest generation of AI coding tools.
Key Themes
1. The Evolution of AI-Assisted Development
The presenters explained the progression from:
- Statistical code completion (~2014),
- GitHub Copilot-style code suggestions,
- Chat-based coding assistants,
- Agentic coding systems that can plan, use tools, and perform multi-step tasks,
- Toward autonomous engineering harnesses that can work independently for longer periods.
2. Understanding What LLMs Actually Do
A major message was that LLMs are still probabilistic token predictors rather than true reasoning systems. Even modern reasoning models remain next-token predictors that have been trained to spend more computation on intermediate reasoning steps. This explains both their power and their tendency to hallucinate.
Exercise 1: "Write me a TODO App"
Participants were asked to give a coding agent a deliberately vague prompt:
"Write me a TODO App!"
The goal was to observe:
- What the agent creates from minimal instructions.
- How different groups obtain different implementations.
- Whether the generated application is actually useful, deployable, or maintainable.
This led to a discussion about whether AI lowers the barrier to software development and whether anyone can now be a developer. The conclusion was nuanced: generating code is easy, but evaluating correctness, safety, maintainability, and business value still requires engineering judgment.
3. How Coding Agents Work
The workshop explained the architecture behind modern coding agents:
- The user interacts through an IDE or harness.
- The harness injects tools and instructions into the LLM.
- The LLM decides when to call tools.
- Tools are executed through MCP (Model Context Protocol) servers.
- Results are fed back into the model for further reasoning.
The ReAct (Reason + Act) pattern and reflection loops were introduced as key mechanisms that make agents more capable than simple chatbots.
4. Context Engineering
A major section focused on controlling what information an AI sees.
Participants learned:
- How to use AGENTS.md or CLAUDE.md files as project entry points.
- How to structure documentation for on-demand loading.
- How skills and subagents can provide specialized capabilities.
- Why more context is not always better due to overload, noise, cost, and loss of focus.
Exercise 2: Controlling the Agent
Participants revisited their TODO app and:
- Defined clearer requirements.
- Added architecture and technology preferences.
- Created documentation and AGENTS files.
- Experimented with planning modes and custom skills.
The objective was to demonstrate that better context leads to better outcomes and that prompt quality alone is not enough—structured context matters.
5. Harness Engineering
The workshop distinguished context engineering (what the model knows) from harness engineering (how the model executes).
Topics included:
- Hooks and workflow automation.
- Guardrails and approval systems.
- Secret scanning.
- Tool restrictions.
- Deterministic controls around probabilistic models.
The key message was that prompts alone are insufficient; important constraints must be enforced through the tooling infrastructure.
6. Security, Trust, and Responsible AI
The presenters highlighted several risks of vibe coding:
- Insecure defaults.
- Hardcoded secrets.
- Hallucinated or malicious dependencies.
- Prompt injection attacks.
- Privacy and intellectual property concerns.
They emphasized a shift from "trust but verify" to "don't trust—enforce" through testing, scanners, policies, and controlled environments. The workshop also discussed accountability, governance, sustainability, and human responsibility when using AI-generated code.
Exercise 3: Breaking the App
Participants were asked to extend or modify their AI-generated TODO application by introducing significant requirement changes such as:
- Authentication,
- Design and UX changes,
- Framework or language migrations.
This exercise illustrated how quickly weaknesses in AI-generated architectures emerge when requirements evolve and reinforced the importance of maintainability and sound design.
Final Takeaways
The workshop concluded with several core lessons:
- AI dramatically increases development speed, but speed does not guarantee quality.
- Software engineering is shifting from writing code to specifying intent, reviewing output, and managing change.
- Human judgment remains essential.
- AI providers should be treated like any other dependency, with contingency plans for outages, costs, and vendor lock-in.
- Sandboxing, testing, code reviews, and specification-driven development are critical safeguards.
- Vibe coding is excellent for prototyping and acceleration, but it does not eliminate the need for architecture, verification, security, and maintainability practices.
In one sentence: the session demonstrated that AI can generate software remarkably quickly, but successful software engineering still depends on careful context design, execution controls, verification, security practices, and human oversight.
Share via:
Read more
-

June 29, 2026
Portugal's State Reform in the Age of AI
What Governments Can Learn from a New Model of Public Administration
-

May 14, 2026
The geopolitics of data sovereignty
The political, economic, and strategic battle over digital trust
-

March 25, 2026
Swiss AI Magazine 2026 Launch
A recap of the Swiss AI Magazine 2026 launch event in Zurich at Headsquarter.
-

March 11, 2026
How to create real business value from AI
Insights from the First Swiss AI Summit Community Event of 2026
-

February 13, 2026
Agentic AI Orchestration
Swiss AI Summit 2025 Keynote with Georg M. V. Olowson from IBM.
-

February 12, 2026
Driving Scalable AI Adoption
Swiss AI Summit 2025 Keynote with Sergio Gago, CTO @ Cloudera
-

February 11, 2026
Embedded Intelligence
Swiss AI Summit 2025 Keynote with Nadine Ebmeyer, CEO @ BANQR
-

February 10, 2026
Enterprise AI Beyond the Hype
Swiss AI Summit 2025 Keynote with Dr. Dorian Selz, Founder & CEO @ Squirro AG
-

February 9, 2026
From AI Ambition to Scalable Impact
Swiss AI Summit 2025 Keynote with Wanja Bont, Partner @ PVL Partners
-
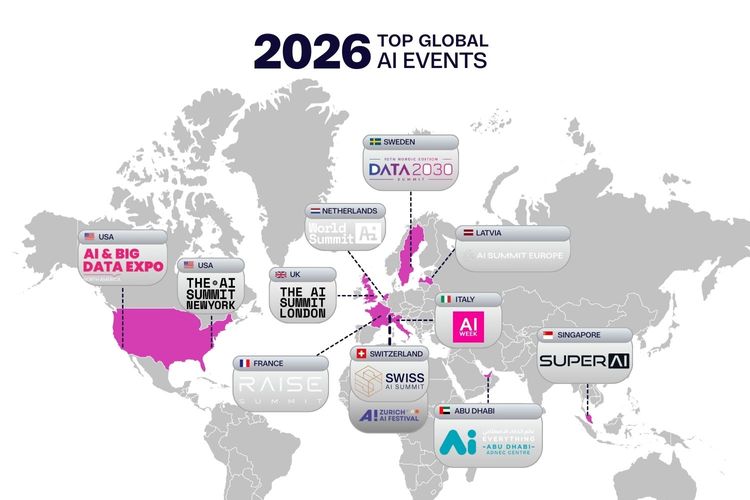
February 6, 2026
Swiss AI Summit listed as a top Global AI Event
Read more about the Article and our Listing by DigitalMara.
-

February 5, 2026
EU-INC. One Legal Entity, One AI Rulebook:
What the EU’s Single Market Vision Means for Tech Companies and AI Innovation
-

November 2, 2025
Interview with: Lauren Hawker Zafer
How Squirro’s Lauren Hawker Zafer views Zurich’s growing AI ecosystem
-

October 8, 2025
PRESS RELEASE: SwissCognitive and Swiss AI Summit join forces
Strengthening business-driven AI adoption and dialogue in Switzerland and beyond
-

October 1, 2025
Article: General-Purpose AI Code of Practice
From Voluntary Code to Strategic Standard: leveraging the GPAI Code of Practice.
-

September 29, 2025
News: The Swiss AI Summit Ecosystem
Switzerland's holistic Platform for AI Innovation
-

September 10, 2025
Article: Escaping the 85% Failure Trap:
Boost Your AI with Quantum-Enhanced Time Series Forecasting
-

September 10, 2025
Article: AI as the Brain of Tomorrow’s Financial System
Insights from Pathway 2035 for Financial Innovation – Your Navigator
-

September 8, 2025
Article: Shaping the Future
AI for Good Global Summit 2025 as the UN’s Premier Forum for AI Innovation
-

September 7, 2025
Article: Unlocking Generative AI in Finance
Solving Complex Data Challenges for Central Banks and Government Authorities
-

September 3, 2025
Article: THE FIVE TRUTHS OF AI - 2025 PERSPECTIVE
Let's explore the evolved "5 Truths of AI" that have emerged in 2025.
-

September 2, 2025
Article: Masumi - The PayPal for AI Agents
“We want to build the PayPal for AI agents.”








































Share via: